大模型部署指南之 LMDeploy 篇:从模型压缩到生产级API的完整武器库
一、LMDeploy 是什么?
LMDeploy 是一个用于大型语言模型(LLMs)和视觉-语言模型(VLMs)压缩、部署和服务的 Python 库。 其核心推理引擎包括 TurboMind 引擎和 PyTorch 引擎。前者由 C++ 和 CUDA 开发,致力于推理性能的优化,而后者纯 Python 开发,旨在降低开发者的门槛。
1.1 核心功能
- 高效的推理:LMDeploy 开发了
Persistent Batch(即 Continuous Batch),Blocked K/V Cache,动态拆分和融合,张量并行,高效的计算 kernel等重要特性。推理性能是 vLLM 的 1.8 倍。 - 可靠的量化:LMDeploy 支持
权重量化和k/v 量化。4bit 模型推理效率是 FP16 下的 2.4 倍。量化模型的可靠性已通过 OpenCompass 评测得到充分验证。 - 便捷的服务:通过请求分发服务,LMDeploy 支持多模型在多机、多卡上的推理服务。
- 有状态推理:通过 缓存 多轮对话过程中
attention 的 k/v,记住对话历史,从而避免重复处理历史会话。显著提升长文本多轮对话场景中的效率。 - 卓越的兼容性: LMDeploy 支持 KV Cache 量化, AWQ 和 Automatic Prefix Caching 同时使用。
1.2 性能
- LMDeploy
TurboMind引擎拥有卓越的推理能力,在各种规模的模型上,每秒处理的请求数是 vLLM 的 1.36 ~ 1.85 倍。在静态推理能力方面,TurboMind 4bit 模型推理速度(out token/s)远高于 FP16/BF16 推理。在小 batch 时,提高到 2.4 倍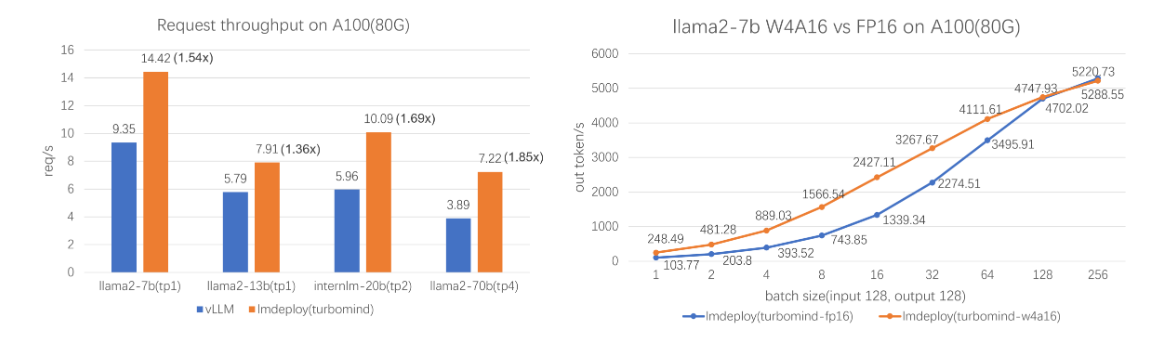
- LMDeploy 支持 2 种推理引擎:
TurboMind和PyTorch,它们侧重不同。前者追求推理性能的极致优化,后者纯用 python 开发,着重降低开发者的门槛。
二、快速开始
2.1 安装
官方推荐在一个干净的 conda 环境下(python3.8 - 3.12)进行安装:
1 | |
2.2 验证
1 | |
2.3 模型仓库
LMDeploy 默认从 HuggingFace 上面下载模型
如果需要从
ModelScope上面下载模型1
2
3pip install modelscope
# 设置环境变量
export LMDEPLOY_USE_MODELSCOPE=True如果要从
openMind Hub上面下载模型1
2
3pip install openmind_hub
# 设置环境变量
export LMDEPLOY_USE_OPENMIND_HUB=True
三、命令说明
3.1 环境检查
1 | |
3.2 模型转换
将模型转换为 LMDeploy 的 Turbomind 优化格式:
1 | |
3.3 模型量化
降低显存占用,提升推理速度:
1 | |
可选参数可不用填写,使用默认的即可,所以命令可以简化为:
1 | |
3.4 交互式对话
1 | |
3.5 服务部署
启动默认服务(端口 23333):
1 | |
四、模型量化
LMDeploy 支持多种量化策略,包括
离线量化:4-bit权重量化、8-bit权重量化
在线量化:KV Cache量化
4.1 INT4 模型量化和部署
LMDeploy TurboMind 引擎支持由 AWQ 和 GPTQ 两种量化方法量化的 4bit 模型的推理。然而,LMDeploy 量化模块目前仅支持 AWQ 量化算法。
量化
1
lmdeploy lite auto_awq internlm/internlm2_5-7b-chat --work-dir internlm2_5-7b-chat-4bit验证
1
lmdeploy chat ./internlm2_5-7b-chat-4bit --model-format awq部署
1
2
3
4# 部署推理服务
lmdeploy serve api_server ./internlm2_5-7b-chat-4bit --backend turbomind --model-format awq
# 部署测试
lmdeploy serve api_client http://0.0.0.0:23333
注意:
- 量化时出现
Out of Memory显存不够:可以通过减小传参--calib-seqlen,增大传参--calib-samples,并使用--batch-size为 1。 - 量化时,无法链接
huggingface并下载数据集。可以尝试使用镜像,export HF_ENDPOINT=https://hf-mirror.com。
4.2 W8A8 LLM 模型部署
LMDeploy 提供了使用 8-bit 整数(INT8)和浮点数(FP8)对神经网络模型进行量化和推理的功能。
进行 8-bit 权重量化需要经历以下三步: 1. 权重平滑:首先对语言模型的权重进行平滑处理,以便更好地进行量化。 2. 模块替换:使用 QRMSNorm 和 QLinear 模块替换原模型 DecoderLayer 中的 RMSNorm 模块和 nn.Linear 模块。lmdeploy/pytorch/models/q_modules.py 文件中定义了这些量化模块。 3. 保存量化模型:完成上述必要的替换后,我们即可保存新的量化模型。
量化
int8
1
lmdeploy lite smooth_quant internlm/internlm2_5-7b-chat --work-dir ./internlm2_5-7b-chat-int8 --quant-dtype int8fp8
1
lmdeploy lite smooth_quant internlm/internlm2_5-7b-chat --work-dir ./internlm2_5-7b-chat-fp8 --quant-dtype fp8
部署
1
2
3
4# 部署推理服务
lmdeploy serve api_server ./internlm2_5-7b-chat-int8 --backend pytorch
# 部署测试
lmdeploy serve api_client http://0.0.0.0:23333
4.3 Key-Value(KV) Cache 量化【推荐】
自 v0.4.0 起,LMDeploy 支持在线 kv cache int4/int8 量化,量化方式为 per-head per-token 的非对称量化。原来的 kv 离线量化方式移除。
LMDeploy kv 量化具备以下优势: 1. 量化不需要校准数据集 2. 支持 volta 架构(sm70)及以上的所有显卡型号 3. kv int8 量化精度几乎无损,kv int4 量化精度在可接受范围之内 4. 推理高效,在 llama2-7b 上加入 int8/int4 kv 量化,RPS 相较于 fp16 分别提升近 30% 和 40%
推理服务
1 | |
五、API 调用
5.1 REST API
查看模型列表
v1/models1
curl http://{server_ip}:{server_port}/v1/models对话
v1/chat/completions1
2
3
4
5
6curl http://{server_ip}:{server_port}/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "internlm-chat-7b",
"messages": [{"role": "user", "content": "Hello! How are you?"}]
}'文本补全
v1/completions1
2
3
4
5
6curl http://{server_ip}:{server_port}/v1/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "llama",
"prompt": "two steps to build a house:"
}'交互式对话
v1/chat/interactive1
2
3
4
5
6
7curl http://{server_ip}:{server_port}/v1/chat/interactive \
-H "Content-Type: application/json" \
-d '{
"prompt": "Hello! How are you?",
"session_id": 1,
"interactive_mode": true
}'
六、高级功能
6.1 对接可视化工具
搭配 OpenWebUI:
1 | |
注意:
- 通过访问
http://localhost:8080使用 Web 界面。 - 不设置
OPENAI_API_BASE_URL环境变量- 可以通过在 web 界面配置中手动设置 API 地址(
头像->设置->外部连接->+->URL->密匙->保存) - web 界面左上角选择对应模型即可
- 可以通过在 web 界面配置中手动设置 API 地址(
七、总结
LMDeploy 是 企业级大模型本地化部署的高效工具,尤其适合:
- 🔒 隐私敏感场景:数据完全本地处理
- ⚡ 高性能需求:量化与并行优化显著降低推理成本
- 🛠️ 快速集成:OpenAI 兼容 API 无缝对接现有系统
资源推荐: