大模型微调指南之 LLaMA-Factory 篇:一键启动LLaMA系列模型高效微调
一、简介
LLaMA-Factory 是一个用于训练和微调模型的工具。它支持全参数微调、LoRA 微调、QLoRA 微调、模型评估、模型推理和模型导出等功能。
二、如何安装
2.1 安装
1 | |
2.2 校验
1 | |
三、开始使用
3.1 可视化界面
1 | |
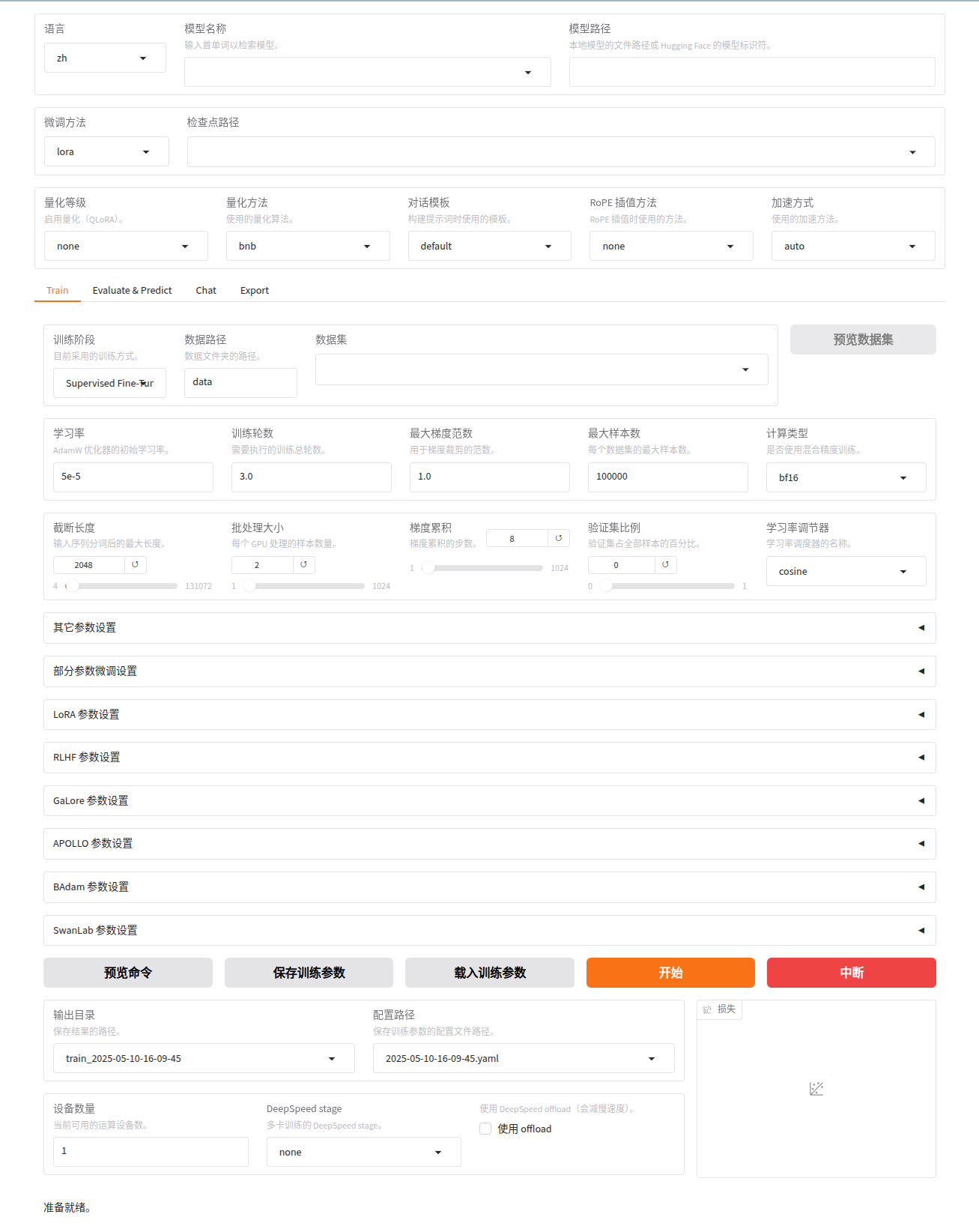
WebUI 主要分为四个界面:训练、评估与预测、对话、导出。
- 训练:
- 在开始训练模型之前,您需要指定的参数有:
- 模型名称及路径
- 训练阶段
- 微调方法
- 训练数据集
- 学习率、训练轮数等训练参数
- 微调参数等其他参数
- 输出目录及配置路径
随后,点击 开始 按钮开始训练模型。
备注:
关于断点重连:适配器断点保存于output_dir目录下,请指定检查点路径以加载断点继续训练。
如果需要使用自定义数据集,需要在data/data_info.json中添加自定义数据集描述并确保数据集格式正确,否则可能会导致训练失败。
评估预测
- 模型训练完毕后,可以通过在评估与预测界面通过指定
模型及检查点路径在指定数据集上进行评估。
- 模型训练完毕后,可以通过在评估与预测界面通过指定
对话
- 通过在对话界面指定
模型、检查点路径及推理引擎后输入对话内容与模型进行对话观察效果。
- 通过在对话界面指定
导出
- 如果对模型效果满意并需要导出模型,您可以在导出界面通过指定
模型、检查点路径、分块大小、导出量化等级及校准数据集、导出设备、导出目录等参数后点击导出按钮导出模型。
- 如果对模型效果满意并需要导出模型,您可以在导出界面通过指定
3.2 使用命令行
3.2.1 模型微调训练
在 examples/train_lora 目录下有多个 LoRA 微调示例,以 llama3_lora_sft.yaml 为例,命令如下:
1 | |
备注:
LLaMA-Factory 默认使用所有可见的计算设备。根据需求可通过CUDA_VISIBLE_DEVICES或ASCEND_RT_VISIBLE_DEVICES指定计算设备。
参数说明:
| 名称 | 描述 |
|---|---|
| model_name_or_path | 模型名称或路径(指定本地路径,或从 huggingface 上下载) |
| stage | 训练阶段,可选: rm(reward modeling), pt(pretrain), sft(Supervised Fine-Tuning), PPO, DPO, KTO, ORPO |
| do_train | true 用于训练, false 用于评估 |
| finetuning_type | 微调方式。可选: freeze, lora, full |
| lora_target | 采取 LoRA 方法的目标模块,默认值为 all。 |
| dataset | 使用的数据集,使用”,”分隔多个数据集 |
| template | 数据集模板,请保证数据集模板与模型相对应。 |
| output_dir | 输出路径 |
| logging_steps | 日志输出步数间隔 |
| save_steps | 模型断点保存间隔 |
| overwrite_output_dir | 是否允许覆盖输出目录 |
| per_device_train_batch_size | 每个设备上训练的批次大小 |
| gradient_accumulation_steps | 梯度积累步数 |
| max_grad_norm | 梯度裁剪阈值 |
| learning_rate | 学习率 |
| lr_scheduler_type | 学习率曲线,可选 linear, cosine, polynomial, constant 等。 |
| num_train_epochs | 训练周期数 |
| bf16 | 是否使用 bf16 格式 |
| warmup_ratio | 学习率预热比例 |
| warmup_steps | 学习率预热步数 |
| push_to_hub | 是否推送模型到 Huggingface |
目录说明:
examples/train_full:包含多个全参数微调示例。examples/train_lora:包含多个 LoRA 微调示例。examples/train_qlora:包含多个 QLoRA 微调示例。
3.2.2 模型合并
在 examples/merge_lora 目录下有多个模型合并示例,以 llama3_lora_sft.yaml 为例,命令如下:
1 | |
adapter_name_or_path 需要与微调中的适配器输出路径 output_dir 相对应。export_quantization_bit 为导出模型量化等级,可选 2, 3, 4, 8。
目录说明:
examples/merge_lora:包含多个 LoRA 合并示例。
3.2.3 模型推理
在 examples/inference 目录下有多个模型推理示例,以 llama3_lora_sft.yaml 为例,命令如下:
1 | |
参数说明:
| 名称 | 描述 |
|---|---|
| model_name_or_path | 模型名称或路径(指定本地路径,或从HuggingFace Hub下载) |
| adapter_name_or_path | 适配器检查点路径(用于 LoRA 等微调方法的预训练适配器) |
| template | 对话模板(需与模型架构匹配,如 LLaMA-2、ChatGLM 等专用模板) |
| infer_backend | 推理引擎(可选:vllm、transformers、lightllm 等) |
3.2.4 模型评估
通用能力评估
1
llamafactory-cli eval examples/train_lora/llama3_lora_eval.yamlNLG 评估
1
llamafactory-cli train examples/extras/nlg_eval/llama3_lora_predict.yaml获得模型的
BLEU和ROUGE分数以评价模型生成质量。评估相关参数
| 参数名称 | 类型 | 描述 | 默认值 | 可选值/备注 |
|---|---|---|---|---|
| task | str | 评估任务名称 | - | mmlu_test, ceval_validation, cmmlu_test |
| task_dir | str | 评估数据集存储目录 | “evaluation” | 相对或绝对路径 |
| batch_size | int | 每个 GPU 的评估批次大小 | 4 | 根据显存调整 |
| seed | int | 随机种子(保证可复现性) | 42 | - |
| lang | str | 评估语言 | “en” | en(英文), zh(中文) |
| n_shot | int | Few-shot 学习使用的示例数量 | 5 | 0 表示 zero-shot |
| save_dir | str | 评估结果保存路径 | None | None 时不保存 |
| download_mode | str | 数据集下载模式 | DownloadMode.REUSE_DATASET_IF_EXISTS | 存在则复用,否则下载 |
四、高级功能
4.1 分布训练
LLaMA-Factory 支持 单机多卡 和 多机多卡 分布式训练。同时也支持 DDP , DeepSpeed 和 FSDP 三种分布式引擎。
- DDP (DistributedDataParallel) 通过实现模型并行和数据并行实现训练加速。 使用
DDP的程序需要生成多个进程并且为每个进程创建一个DDP实例,他们之间通过torch.distributed库同步。 - DeepSpeed 是微软开发的分布式训练引擎,并提供
ZeRO(Zero Redundancy Optimizer)、offload、Sparse Attention、1 bit Adam、流水线并行等优化技术。 - FSDP 通过全切片数据并行技术(Fully Sharded Data Parallel)来处理更多更大的模型。在
DDP中,每张 GPU 都各自保留了一份完整的模型参数和优化器参数。而FSDP切分了模型参数、梯度与优化器参数,使得每张GPU只保留这些参数的一部分。 除了并行技术之外,FSDP还支持将模型参数卸载至 CPU,从而进一步降低显存需求。
| 引擎 | 数据切分 | 模型切分 | 优化器切分 | 参数卸载 |
|---|---|---|---|---|
| DDP | 支持 | 不支持 | 不支持 | 不支持 |
| DeepSpeed | 支持 | 支持 | 支持 | 支持 |
| FSDP | 支持 | 支持 | 支持 | 支持 |
4.2 DeepSpeed
由于 DeepSpeed 的显存优化技术,使得 DeepSpeed 在显存占用上具有明显优势,因此推荐使用 DeepSpeed 进行训练。
DeepSpeed 是由微软开发的一个开源深度学习优化库,旨在提高大模型训练的效率和速度。在使用 DeepSpeed 之前,您需要先估计训练任务的显存大小,再根据任务需求与资源情况选择合适的 ZeRO 阶段。
- ZeRO-1(优化器状态分片): 仅划分优化器参数,每个 GPU 各有一份完整的模型参数与梯度。
- ZeRO-2(+梯度分片): 划分优化器参数与梯度,每个 GPU 各有一份完整的模型参数。
- ZeRO-3(+参数分片): 划分优化器参数、梯度与模型参数。
简单来说:从 ZeRO-1 到 ZeRO-3,阶段数越高,显存需求越小,但是训练速度也依次变慢。此外,设置 offload_param=cpu 参数会大幅减小显存需求,但会极大地使训练速度减慢。因此,如果您有足够的显存, 应当使用 ZeRO-1,并且确保 offload_param=none。
4.2.1 单机多卡
启动 DeepSpeed 引擎,命令如下:
1 | |
该配置文件中配置了 deepspeed 参数,具体如下:
1 | |
4.2.2 多机多卡
1 | |
4.2.3 参数说明
CUDA_VISIBLE_DEVICES:指定进程可见的 GPU 列表。NPROC_PER_NODE:每个节点上的 GPU 数量。
注意:
NPROC_PER_NODE≤CUDA_VISIBLE_DEVICES可见的数量- 所有节点的配置一致。
- 编号映射正确(进程内 GPU 编号从 0 开始)。
4.3 其他参数
更多参数介绍请参考官方文档
五、日志分析
在训练过程中,LLaMA-Factory 会输出详细的日志信息,包括训练进度、训练参数、训练时间等。这些日志信息可以帮助我们更好地了解训练过程,并针对问题进行优化和调整。以下解释训练时的一些参数:
1 | |
参数解释:
单设备批大小(Instantaneous batch size per device)
- 指单个 GPU(或设备)在每次前向传播时处理的样本数量。
- 例如,如果
instantaneous_batch_size_per_device=8,则每个 GPU 一次处理 8 条数据。
设备数(Number of devices)
- 指并行训练的 GPU 数量(数据并行)。
- 例如,使用 4 个 GPU 时,
device_num=4。
梯度累积步数(Gradient accumulation steps)
- 由于显存限制,可能无法直接增大单设备批大小,因此通过多次前向传播累积梯度,再一次性更新参数。通过梯度累积,用较小的单设备批大小模拟大总批大小的训练效果。
- 例如,若
gradient_accumulation_steps=2,则每 2 次前向传播后才执行一次参数更新。
总批大小(Total train batch size)
- 是参数更新时实际使用的全局批量大小。总批大小越大,梯度估计越稳定,但需调整学习率(通常按比例增大)
在 LLaMA Factory 中,总批大小(Total train batch size)、单设备批大小(Instantaneous batch size per device)、设备数(Number of devices) 和 梯度累积步数(Gradient accumulation steps) 的关系可以用以下公式表示:
1 | |
例如:
- 单设备批大小 = 8
- 设备数 = 4
- 梯度累积步数 = 2
- 则总批大小 = 8 x 4 x 2 = 64
参考资料: